Abstract摘要
High benchmark scores on Classical Chinese Poetry (CCP) tasks may arise not from transferable Linguistic-Aesthetic Reasoning, but from a Memorization Illusion — models retrieving canonical texts from pre-training corpora rather than reasoning over formal constraints.
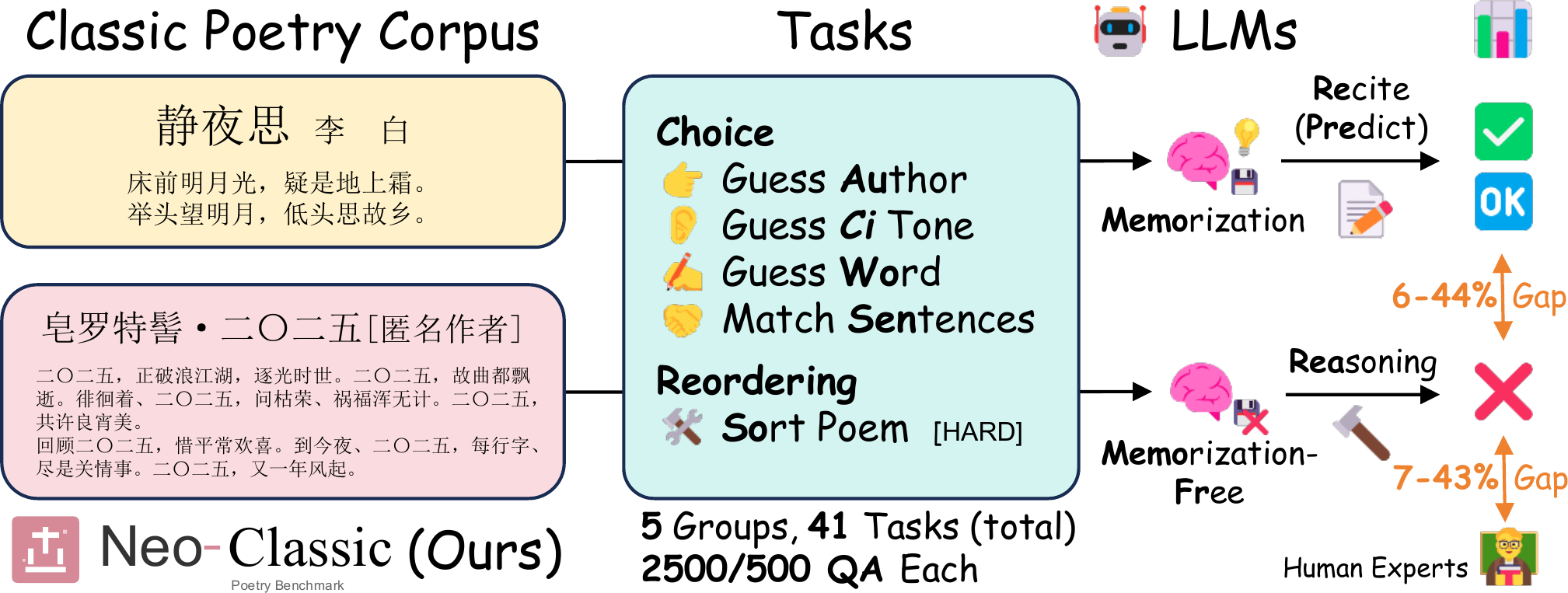
We introduce NEO-CLASSIC, an Out-of-Sample (OOS) evaluation testbed built on 1,406 contemporary poems authored by 30 living poets. These works strictly conform to classical prosodic rules while being absent from historical corpora, enabling clean measurement of the Memorization Gap. Across five diagnostic probes — from authorship attribution to poem-level sentence reordering — we show that SOTA LLMs suffer 20–50% performance drops on contemporary texts and near-total failure on global structural planning tasks.
大语言模型在古典诗词任务上的高分可能并非来自可迁移的语言美学推理能力,而是源于记忆幻觉——模型从预训练语料中直接检索经典文本,而非基于格律约束进行推理。
我们提出 NEO-CLASSIC,一个基于样本外(OOS)评测的测试平台,包含 30 位当代诗人创作的 1,406 首作品。这些作品严格遵守古典格律规范,同时不存在于历史语料库中,从而实现对记忆差距的精准度量。通过五类诊断性探针任务——从作者归属到诗句排序——我们发现,SOTA 大语言模型在当代文本上的表现下降 20–50%,且在全局结构规划任务上几乎完全失败。
Key Findings核心发现
Memorization Gap记忆差距
Performance drops substantially when models shift from historical to contemporary texts, while human experts remain stable.当模型从历史文本转向当代文本时,性能大幅下降,而人类专家表现保持稳定。
Structural Collapse结构性崩溃
Standard LLMs achieve near-zero accuracy on Lü (8-line) reordering. Best model reaches 36% with expert prompting vs. 48% human.标准大模型在律诗(8句)排序任务上准确率接近零。最佳模型在专家提示下仅达 36%,而人类专家为 48%。
Fine-tuning ≠ Reasoning微调 ≠ 推理
Domain-specialized models (Yi-34B, Xunzi) underperform general-purpose SOTA, suggesting scale matters more than domain data.领域微调模型(Yi-34B、荀子)表现不如通用 SOTA 模型,表明模型规模比领域数据更重要。
Benchmark Tasks基准任务
Five behavioral probes targeting different constraint levels of Classical Chinese Poetry:五类行为探针,分别针对古典诗词不同层级的形式约束:
| Probe探针 | Task任务 | Constraint约束层级 | What It Tests测试内容 | Random随机基线 |
|---|---|---|---|---|
| GuessAuthor | Authorship attribution作者归属 | Stylistic风格 | Idiolect extraction without memorization在无记忆辅助下识别个人语体风格 | 25% |
| GuessCiTone | Cipai identification词牌识别 | Phonological音韵 | Character counting & tonal mapping字数统计与平仄映射 | 25% |
| GuessWord | Cloze test填空测试 | Phon.音韵 + Syn.句法 | Constraint recognition & prosodic sensitivity约束识别与声律敏感度 | 25% |
| MatchSentence | Couplet matching联句匹配 | Syntactic句法 | Understanding of Duizhang (parallelism)对仗理解能力 | 25% |
| SortPoem | Sentence reordering诗句排序 | Discourse篇章 | Global planning over Qi-Cheng-Zhuan-He基于起承转合的全局规划 | ~0.002% |
Results实验结果
Lü Sorting Accuracy: The Impact of Expert Prompting律诗排序准确率:专家提示的影响
| Model模型 | Standard标准 | CoT-Expert思维链-专家 | Gap vs. Human与人类差距 |
|---|---|---|---|
| DeepSeek-V3.2 | 0.0% | 16.5% | -31.5 |
| Qwen3-Max | 1.0% | 13.0% | -35.0 |
| Gemini-3-Pro | 3.0% | 36.0% | -12.0 |
| GPT-4o | 0.0% | 0.0% | -48.0 |
| Human Expert人类专家 | 36.6% | 48.0% | — |
Random chance for Lü (8 lines): 1/8! ≈ 0.002%. Even with structured expert-level guidance, the best model trails human experts by 12 percentage points. 律诗(8句)随机正确率:1/8! ≈ 0.002%。即使在结构化专家级提示下,最佳模型仍落后人类专家 12 个百分点。
| # | Model模型 | Author 3-shot3样例 |
Tone std标准 |
Cloze std标准 |
Match std标准 |
Jue 4-line绝句 |
Lü 8-line律诗 |
Avg均分 |
|---|---|---|---|---|---|---|---|---|
| Human Expert人类专家 Expert专家 | 65.0 | 88.0 | 65.0 | 75.0 | 62.0 | 36.6 | 65.3 | |
| Human Players普通玩家 Casual业余 | 39.0 | 46.5 | 48.4 | 48.0 | 47.7 | — | — | |
| 1 | DeepSeek-V3.2 API | 37.2 | 44.8 | 58.3 | 64.0 | 27.4 | 1.0 | 38.8 |
| 2 | Qwen3-Max API | 39.0 | 33.0 | 52.0 | 67.0 | 32.0 | 1.0 | 37.3 |
| 3 | Gemini-3-Pro API | 32.0 | 36.0 | 42.0 | 57.0 | 41.0 | 3.0 | 35.2 |
| 4 | GPT-4o API | 38.3 | 30.3 | 50.2 | 56.6 | 16.2 | 0.0 | 31.9 |
| 5 | Yi-34B Local | 38.0 | 34.0 | 44.0 | 54.0 | 9.0 | 0.0 | 29.8 |
| 6 | Gemini-2.5-Pro API | 30.0 | 27.0 | 50.0 | 52.0 | 19.0 | 0.0 | 29.7 |
| 7 | Qwen3-30B API | 34.0 | 30.0 | 44.0 | 46.0 | 5.0 | 0.0 | 26.5 |
| 8 | Xunzi-Qwen3-8B Domain | 3.0 | 4.0 | 16.0 | 9.0 | 13.0 | 0.0 | 7.5 |
Dataset数据集
Data files follow the naming convention:数据文件命名规则:
{corpus}.{task}.{variant}.jsonl
Corpora: tang, song, tang300, tangsong, today
Tasks: guess_author, guess_word, guess_ci_tone, match_sentence, sort_poem
Variants: standard, fewshot1/3/10, cot, couplets, jue, lyu, lyu_cot_expert
Citation引用
@inproceedings{zhang2026neoclassic,
title={Neo-Classic: A Benchmark for Evaluating Linguistic-Aesthetic Reasoning in Classical Chinese Poetry},
author={Zhang, Han and Gu, Zihan and Wang, Zhiyuan and Ma, Tianyi and Lu, Jiacheng and Zhang, Xinyan and Wei, Yuhao and Hua, Cheng},
booktitle={Proceedings of the 64th Annual Meeting of the Association for Computational Linguistics (ACL)},
year={2026}
}
Acknowledgments致谢
This research originated from the SJTU Classical Chinese Culture Club (guoxue_sjtu@163.com). We are deeply grateful to the 30 contemporary poets who authorized the use of their works for this benchmark.本研究源自上海交通大学国学社(guoxue_sjtu@163.com)。我们衷心感谢 30 位当代诗人授权使用其作品构建本基准测试。
View all 30 contributing poets查看全部 30 位授权诗人
Lin Yuye, Xizhi, Xiyan, Zhou Qinggui, Guanghan Jushi, Baomu, Lingjun, Shaoni, Maoge, Wu Sipeng, Yanchi, Guijia, Chang'an, Chengqing, Huatong, Yang Ruoxuan, Xie Zhongyan, Guiti, Mu Linu, Yun'aimu, Chenlv, Pifu, Mingling Xiaoyue, Wang Qingyan, Nanyang Jushi, Kongke, Shuangxie, Huwulinglong, Sun Zhongyi, Qianwu 林雨夜、希之、溪烟、周庆贵、广寒居士、抱木、令君、韶逆、毛哥、伍思鹏、雁迟、龟家、长安、承青、花桐、杨若萱、谢忠延、归荑、木狸奴、云爱暮、尘旅、蚍蜉、明棂晓月、王清晏、南阳居士、空客、霜写、昈旿昤昽、孙中宜、潜武